在当今严峻的网络安全态势下,安全运营中心(SOC)已成为组织网络防御体系的核心枢纽。其核心使命在于持续监控、检测、分析并响应安全威胁。构建一个高效的SOC绝非易事,它高度依赖于对事件响应效能的精准衡量、科学合理的人员配备策略以及与网络系统的深度集成。本文将围绕这三个关键维度展开探讨。
一、事件响应效能的衡量:从指标到价值
衡量SOC的事件响应效能,不能仅停留在“是否响应”的层面,而应深入评估其响应的速度、准确性和最终效果。这需要建立一套多维度的关键绩效指标(KPI)与关键风险指标(KRI)体系。
- 时效性指标:这是最基础的衡量标准。主要包括:
- 平均检测时间(MTTD):从威胁发生到被SOC识别所花费的平均时间。缩短MTTD意味着更早的威胁发现。
- 平均响应时间(MTTR):从确认事件到启动遏制、修复措施的平均时间。MTTR直接体现了团队的应急反应能力。
- 平均遏制/修复时间(MTTC/MTTR):指完全控制事件影响并恢复系统到正常状态所需的时间。
- 准确性指标:
- 误报率:自动化工具或分析师误判的正常行为比例。高误报率会严重消耗分析师精力,导致“警报疲劳”。
- 漏报率:未能检测到的真实威胁比例(通常较难直接衡量,可通过红蓝演练、威胁狩猎发现)。
- 事件分类与优先级判定的准确率:确保资源被优先用于处理高风险事件。
- 效果与效率指标:
- 事件解决率/关闭率:在规定时间内成功处理并关闭的事件比例。
- 平均事件处理成本:综合人力、技术、业务中断等成本,衡量响应的经济性。
- 对业务影响的降低程度:这是衡量响应效能的终极标准,可通过中断时间、数据损失量、财务损失等业务指标来量化。
有效的衡量不仅是报告工具,更是驱动SOC持续改进的引擎。通过定期复盘(如举行事故后评审),能将指标数据转化为具体的流程优化、技术调优和人员培训行动。
二、人员配备:构建分层协作的防御团队
SOC的人员配备绝非简单的“人头数”问题,而是涉及角色、技能、梯队和运维模式的综合设计。
- 分层技能模型(Tiered Model):
- Tier 1 监控与分析员:负责7x24小时监控警报,进行初级分类、排查和分流。需要广泛的网络与安全基础知识。
- Tier 2 事件响应分析师:负责深入调查Tier1升级的复杂事件,进行威胁溯源、影响评估并执行遏制措施。需要更深的取证、恶意软件分析等专业技能。
- Tier 3 威胁猎手与高级专家:主动搜寻潜伏威胁,分析高级持续性威胁(APT),并负责优化检测规则、工具和流程。通常是某一领域的专家(如逆向工程、情报分析)。
- SOC经理/协调员:负责日常运营、资源调度、与内外部的沟通协调以及流程管理。
- 配备考量因素:
- 业务规模与风险状况:金融、政府等高价值目标需要更密集的覆盖。
- 技术栈复杂度:管理的资产、日志源、安全工具越多,对人员的数量和技能要求越高。
- 运维模式:是内部自建、完全外包还是混合(Co-managed)模式?这决定了核心团队与外部支持的比例。
- 人员流失与倦怠:SOC工作压力大,需规划合理的轮班制度、职业发展路径和知识管理,以维持团队稳定与活力。
三、网络系统集成:打造一体化的神经中枢
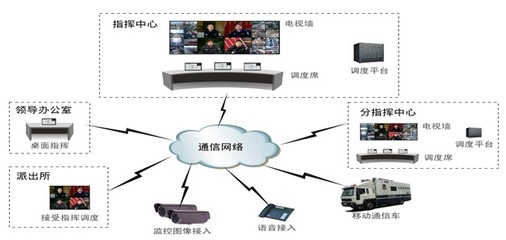
SOC的“眼睛”和“手臂”来自与整个网络及IT系统的深度集成。集成程度直接决定了其可见性和响应能力。
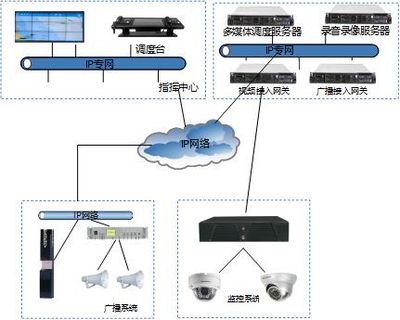
- 数据层集成:
- 全量日志与流量收集:集成网络设备(防火墙、路由器)、安全设备(IDS/IPS、WAF)、终端(EDR)、服务器、云环境、业务应用等所有可能产生安全相关数据的源。
- 安全信息和事件管理(SIEM)平台:作为数据中枢,实现日志的归一化、关联分析和长期存储。与威胁情报平台(TIP)集成,能为数据注入上下文。
- 控制层集成:
- 安全编排、自动化与响应(SOAR)平台:这是提升响应效率的关键。通过预定义的剧本(Playbook),能将SIEM中的警报与防火墙、交换机、终端安全软件等执行节点联动,实现如自动封禁恶意IP、隔离中毒主机等操作,将MTTR从小时级降至分钟级。
- 集成原则:
- 标准化:优先采用Syslog、API等标准接口。
- 高可用与性能:集成不能成为单点故障或性能瓶颈。
- 权限最小化:SOC系统在集成时获得的访问权限应严格遵循最小特权原则,防止自身成为攻击跳板。
结论
一个卓越的SOC,是精准的度量体系、专业化的人才团队与高度集成的技术平台三者融合的产物。衡量事件响应效能指明了改进的方向;科学的人员配备提供了持续作战的人力保障;而深度的网络系统集成则赋予了SOC感知和行动的“超能力”。组织在建设和运营SOC时,必须将这三者作为一个有机整体来规划与优化,使其从“成本中心”真正转变为保障业务安全的“价值中心”,在动态变化的网络威胁面前,构筑起一道智能、敏捷且坚韧的防线。